在“组件-通用”里选择报表组件,可以制作多表头复杂报表
# 报表计算模型介绍
在复杂报表中单元格之间存在依赖关系,对于任意一个单元格都可以设置它的左父格与上父格。单元格父格是可选的,默认情况下,单元格的左父格就是其最近左边与其位于同一行的单元格;上父格则是其最近上方与其位于同一列的的单元格。如果一个单元格位于第一行,那默认它就没有上父格,同样,如果位于第一列,默认它就没有左父格。打开报表设计器,选中任意单元格,都可以在其属性面板看到它的默认上父格或左父格,如下
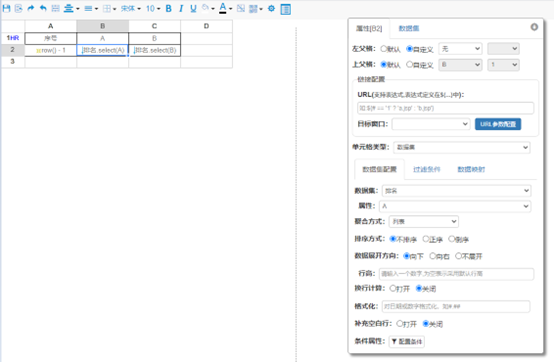
如上图所示,对于某一特定单元格,我们可以手动更改它的左父格或上父格。任意单元格在绑定数据集中某个字段会,如果这个字段有一条以上的数据,那么单元格就可以展开以显示这些数据。对于父格而言,父格展开时会带动子格一起展开,如父格向下展开,则带其下所有子格及子格的子格一起向下展开;同时,如果子格中绑定的数据集与父格中数据集同属一个,则子格中的数据将受父格限制。子格绑定的数据集字段数据在展开时,同样也会带动其下子格一起展开,而当前子格的父格如与子格处于同一行或列,则会将父格拉大。利用上述迭代单元格的特性,我们就可以制作出各种复杂的报表样式,掌握了这一报表计算模型的特点,是开发报表的前提。
# 数据集选择
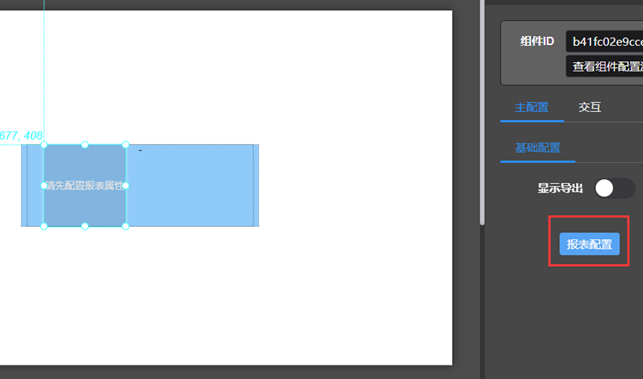
选中报表,点击报表配置,在操作面板选择数据集页签,页签下可以引用数据集模块创建好的数据集


双击要使用的数据集,将数据集引入报表,自动列出数据集的全部字段[数据集的引入见数据集管理]
左侧选中某个单元格,双击字段即可给单元格绑定字段。
# 参数与筛选器
参数指的是从报表筛选器传入报表的值,在DataSoli中,下面介绍如何SQL数据集如何定义参数。
# SQL数据集参数
在SQL数据集SQL编辑器中需要添加动态参数,供报表筛选器绑定,动态参数形式如下:
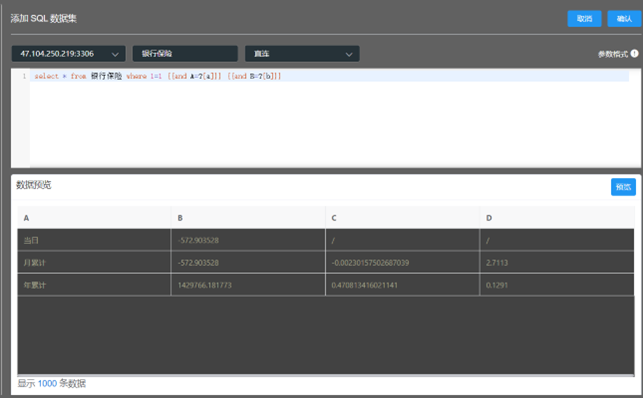
select * from 表名where 1=1 {{and A=?[a]}} {{and B=?[b]}}
【可在当前页参数格式处查看】其中a,b代表参数名称,A,B为列名,报表查询时如果没有参数值,则该条件不生效,相当于不存在。如果有参数值,则自动加到列过滤。写好sql后点击阅览按钮,下方会刷出数据、字段信息以及识别的参数
# 筛选器
在datasoli中,复杂报表筛选功能由表单组件与复杂报表组件联动实现。
- 新平台参数格式 格式:
{{ 筛选语句 ?[动态参数]}}
案例:
select * from table where 1=1 {{ and 种类 =?[a] }}
[] 用于存放参数,该参数仅适用于报表组件之间的交互,其他组件交互不执行,旧写法和新写法不能同时使用。
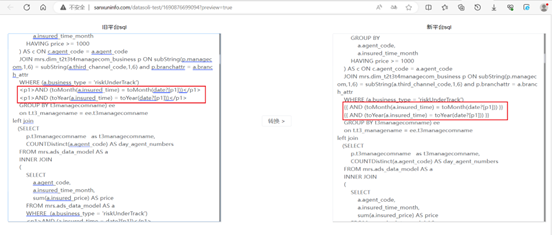
- 旧新动态参数转换页面
外网访问连接:点击查看案例 (opens new window)
案例:
- 新动态参数使用及报表筛选 当前数据集换行问题已解决,通过转换sql可正常使用
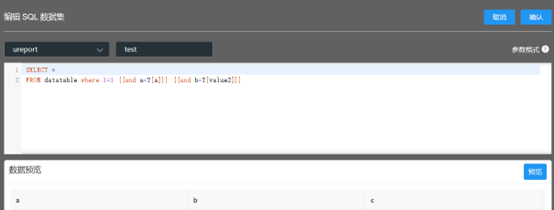
通过输入框筛选报表数据,需要设置一下配置,如下:
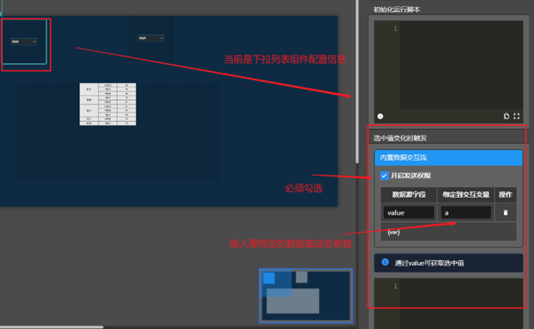
完成报表,如图:

# 表达式
在报表使用过程当中,不可避免的要使用函数及表达式实现一些数据的计算,在复杂报表组件当中,很多地方都支持编写表达式,比如最典型的我们可以将单元格类型改为“表达式”,这样就可以在下面的表达式编辑器里输入相应的表达式与函数,除此之外,复杂报表组件还允许我们在条件、图片来源、二维码数据来源等地方使用表达式,所以学习并掌握复杂报表组件中提供的表达式,是制作复杂报表的前提。
# 基本语法
与一般的编程语言类似,复杂报表组件中的表达式也有一些基本的数据类型,比如数字、字符串、布尔值等。上述的有三种基本的数据类型,可以单独使用,也可以用“+”、"-"、"*"、"/"、"%"连接,进行组合运算,如下表所示:
| 符号 | 描述 | 示例 |
|---|---|---|
| + | 求两个数的和,或者是连接两个值 | 21+31,这就表示求这两个数的和,结果就是52,“值:”+331则表示连接两个值,其结果就是“值:331” |
| - | 求两个数差 | 21 - 31,这就表示求这两个数的差,结果就是-10 |
| * | 求两个数的乘积 | 3*6,结果就是18 |
| / | 求两个数除的结果 | 6/3,结果就是2,如果除不尽,则会保留8位小数 |
| % | 求两个数除的余值 | 5%3,结果是2;6%2结果是0 |
复杂报表组件中还提供了几种类型的条件判断运算符,我们首先来看一下三元表达式。
# 三元表达式
基本所有的语言都支持三元表达式判断,它的特点是简洁明晰,可以用最少的代码进行条件判断,复杂报表组件中的三元表达式语法结构如下图所示:

可以看到,和普通的三元表达式一样,它的第一部分是条件部分,条件部分可以有多个条件(用and或or连接),“?”后面是条件满足后执行并返回的表达式部分,“:”后面则是条件不满足时执行返回的表达式部分。
| 三元表达式示例 | 说明 |
|---|---|
| A1>1000 ? "正常值" : "低值" | 表达式计算时,先取到A1单元格的值,判断值是否大于1000,如果是返回“正常值”字符串,否则返回“低值”字符串 |
| A1>1000 and A1<20000 ? "正常值" : "修正值:"+(A1+100) | 条件部分,判断A1值是否大于1000且小于20000,如果是返回"正常值",否则返回字符串” |
# if判断
复杂报表组件中if判断表达式语法结构如下图所示:
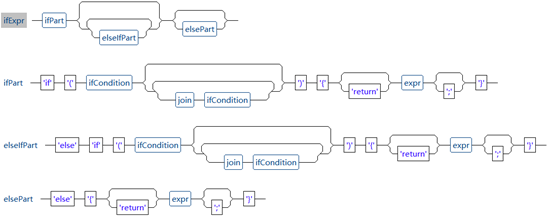
从图中可以看到,if判断表达式则一个if条件判断部分加若干个可选的elseif条件判断部分,最后再加一个可选的else部分构成,语法结构类似java或javascript。
| if判断表达式示例 | 说明 |
|---|---|
| if(A1>1000){return "正常值"} | 判断A1单元格的值是不是大于1000,如果是返回”正常值“字符串,否则什么都不做 |
| if(A1>1000){return "正常值"}else{"低值";} | 判断A1单元格的值是不是大于1000,如果是返回”正常值“字符串,否则返回”低值“字符串。这里需要注意的是,在if表达式中,return关键字是可选的,同是行尾添加';'也是可选的,这主要是为了照顾一些java及javascript程序的习惯 |
| if(A1>1000 and A1<20000){return "正常值:"+A1}else if(A>20000 and A1<40000){return "超高值"}else{"低值"} | 在这个例子当中,条件部分添加了多个组合条件,同时elseif多重判断 |
# case判断
case判断是复杂报表组件中提供的另一种条件判断形式,与if判断有些类似,但case判断看起来更为简洁,其语法结构图如下所示:
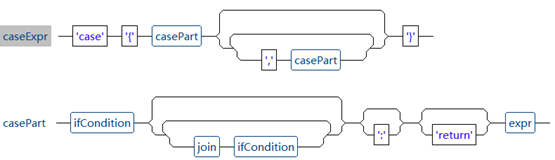
可以看到,case判断要由case{...}包裹,然后是若干条件加返回值。
| case表达式示例 | 说明 |
|---|---|
| case{A1==100 return "正常值",A1>100 and A1<1000 return '偏高'} | 有两个条件,分别返回不同的值 |
| case{A1==100 return "正常值", A1>100 and A1<1000 '偏高'} | 在case表达式中,return关键字同样是可选 |
# 单元格引用
在报表当中,大多数的计算都是针对单元格或与单元格有关,因为报表中单元格多数都与数据绑定,而数据往往又是多条,所以计算后的报表一个单元格会产生多个,这样对于单元格的引用就变的比较复杂。在复杂报表组件中,引用的目标单元格是相对当前单元格来进行计算的,引用方法就是直接在表达式里书写单元格名称,比如引用A1单元格,就直接写A1即可,如下面的例子:

在上图当中,我们在D1单元格中输入表达式A1,这就表示,在D1单元格里填入相对当前D1单元格的A1单元格的值,运行后的效果如下:
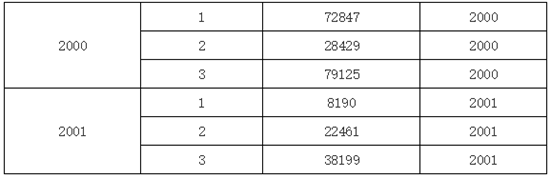
可以看到,因为D1是A1的子格,A1单元格绑定的数据就是分组结构,根据当前D1单元格的位置,就产生的上图所示的结果。如果在D1单元格中输入B1,那么运行后的效果又是下图的样子:
同样,如果在D1中输入表达式C1,那么运行后将会在每个D1单元格中填入与D1单元格位于同一行的C1单元格的值,运行结果这里就不再贴出来了。
通过上面的例子我们可以看到,复杂报表组件中某个单元格的表达式引用目标单元格,首先判断的是目标单元格与其所在单元格是否位于同一行或行,如果是则直接取对应行或列上目标单元格的值。如果当前单元格与目标单元格不在同一行或列,那情况又不一样了,我们来看下一个例子。

在上面的例子中,我们在C2单元格的表达式中输入B1,表示取B1单元格的值,但B1单元格又和C2不在同一行或列上,同时B1单元格展开后会有多个值,但B1单元格和C2单元格都拥有一个共同的父格或间接父格A1(C2单元格的左父格是B2,而B2单元格的左父格又是A1,所以A1是C2单元格的间接左父格),所以它会取他们共同父格A1下所有B1的值,运行结果如下图所示:
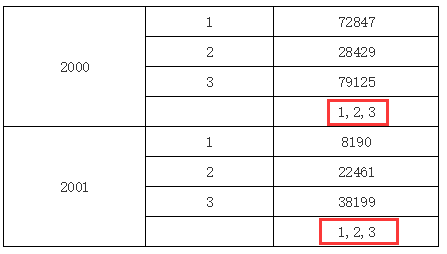
在复杂报表组件中,如果取到值超过一个,输出时多个值间以“,”分隔,如上图所示
目标格获取原则:由上面的例子可以看出,复杂报表组件中单元格表达式在取目标格值时,优先考虑的是目标格是否与其位于同一行或列,如果是则取与其位于同一行或列的目标单元格,如果不是,则取与当前单元格有共同父格的所有目标单元格,如果他们有共同的上父格或共同的左父格,那么就取共同上父格与共同左格交集部分的目标单元格;如果他们没有共同的父格,那么就取迭代后所有的目标单元格。
针对上面的例子,如果我们在上面的单元格中输入C1,那结果又不一样;因为C1是C2的上父格,所以将直接取与其位于同一列的上父格单元格的值,运行效果如下图所示:
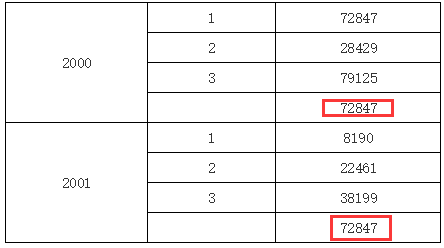
再看下面的报表示例:

在上面的例子中,B2单元格表达里输入C1,因为B2和C2既不在同一行或列,也没有共同的父格,所以B2中将取到所有的C1单元格的值,如下图所示:
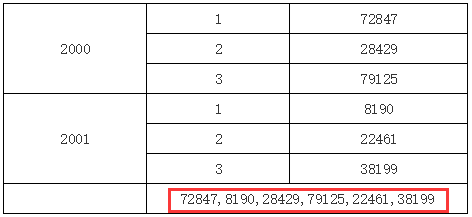
更改父格实现单元格取值。在介绍报表计算模型时,我们多次利用更改当前单元格的上父格或左父格使得当前单元格与目标格处于某个特定的父格下,其原理就来自于此。
# 单元格坐标
为了实现更为复杂的单元格引用,复杂报表组件引用了单元格坐标的概念。单元格坐标,也是相对于当前单元格来进行计算的,同样遵循上面的介绍的优先取同行、同列或共同父格的原则,一个标准的单元格坐标格式如下:
单元格坐标格式 单元格名称
[Li:li,Li-1:li-1,…;Ti:ti,Ti-1:ti-1…]{条件...}
L表示左父格,l表示左父格展示后的序号,序号为负值,表示向上位移;T表示上父格,t表示上父格展开后的序号,序号为负值,表示相对于当前单元格向上位移,正值则表示向下位移,如果只有左父格,那么直接写L部分即可;如果只是上父格,那么前面需要加上“;”号,然后写T部分,后面的大括号中是条件部分,多个条件之间用and/or连接,表示对通过坐标取到的单元格进行条件过滤(如果取到多个单元格的话),条件部分是可选的,相关示例如下:
| 单元格坐标示例 | 说明 |
|---|---|
| C1[A1:2,B1:1] | 在找C1时先找单元格A1展开后的第2格;再找第二个A1下的B1单元格展开后的第一个单元格,然后再找这个B1单元格对应的C1单元格 |
| C2[A1:2,B1:2;C1:3] | 在找C2时,先找A1单元格展开后的第二格,再找第二个A1单元格下B2单元格展开后的第二格,再根据第二个展开的B2单元格找其下名为C2单元格的左子格;然后再找到C1单元格展开后的第三格,再看其下的C2单元格,取C2单元格的交集 |
| C2[A1:2,B2:2]{C2>1000} | 表示取A2单元格展开后的第二格,再取其下B2单元格展开后第二格,再取B2下所有的C2单元格,最后再对取到的C2单元格进行条件过滤,只取出C2单元格值大于1000的所有C2单元格。 |
| C2[A1:2,B2:2]{C2>1000 and C2<10000} | 表示取A2单元格展开后的第二格,再取其下B2单元格展开后第二格,再取B2下所有的C2单元格,最后再对取到的C2单元格进行条件过滤,只取出C2单元格值大于1000且小于10000的所有C2单元格的值。 |
我们来看一个具体的示例,报表模版如下:

在上面的报表模版中,在B2单元格表达式里,我们输入了
C1[A1:2,B1:1]
,这就表示取A1单元格展开后第二格下B1单元格展开后第一格下对应的C1单元格的值,所以运行后我们可以看到如下图所示效果:
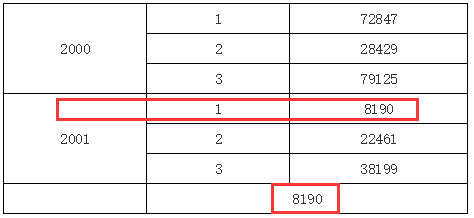
当然,我们可以做一个交叉表,然后通过添加左父格和上父格约束坐标来定位某个特定单元格,这里就不再演示了。在实际应用当中,单元格坐标可以用在诸如同比,环比之类的统计报表当中,这时单元格坐标序号会用一些负值相对当前单元格进行位移,从而实现各种比值的计算。
引用所有单元格:如果我们需要引用所有单元格时,那么只需要在单元格名称后跟”[]“即可,如A1[],表达引用所有A1单元格,而不管当前引用格所在位置,同时在引用所有单元格时,还可以后跟条件,以对引用格做进一步条件限制,如A1[]{@>1000 and @<10000},表示要引用所有的A1单元格,但要求引用的A1单元格值要大于1000同时小于10000,这里的@符号是2.2.3及以后版本新增加的一个表达式符号,专门用于取条件循环中当前循环对象。
我们首先来看一个环比的例子。
# 环比
报表模版如下图所示:

在上面的报表模版中,D2单元格中的表达式为
C2 - C2[A2:-1]
,这就表示在D2单元格中首先取到C2单元格的值, 因为C2单元格与D2位于同一行,所以可以直接取到,且只有一个;下一个C2采用了坐标A2:-1,那就表示取相对于当前单元格的A2单元格上一格(负值表示向上位移)的A2单元格所对应的C2单元格,运行后的效果如下图所示:
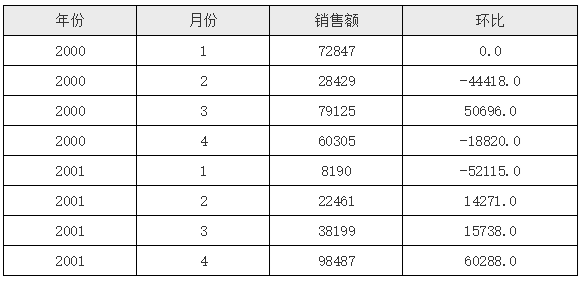
从运行结果中可以看到,第一行环比的值为0,这是因为对于第一行的D2单元格来说,其上一行其实是不存在的,所以复杂报表组件默认就取了第一个C2单元格的值,所以两个值减下来就是0。
下一个例子我们来看看同比。
# 同比
报表模版如下图所示:

在上面的模版当中,D2单元格中首先取到与其同行的C2单元格的值,然后利用单元格坐格,先取到当前D2单元格所在行的A2单元格的上一条A2单元格记录(-1表示坐标上移),然后再取这个A2下对应的C2单元格,但由于其下C2单元格还是有多个,所以这里加了个条件B2==$B2,这里的第一个B2表示当前单元格所在行对应的B2的值,$B2表示坐标定位后C2单元格对应的B2单元格的值,条件就是他们俩要相等,实际上就是月份相等,这样就达到了我们要实现的同比的目的,运行后的效果如下:
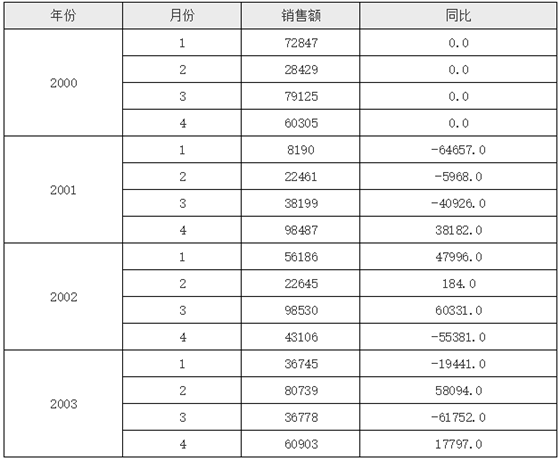
# 关于$B2
在复杂报表组件当中,在单元格名称前加$符号,表示取相对于目标单元格的单元格的值,多用在条件比较当中,比如上面的C2[A2:-1]{B2==$B2},这里的$B2就是指取到的C2单元格对应的B2单元格的值。
在上面的例子中,第一个分组2000下,所有的同比值都为0,这是因为这个分组下不存在A2:-1这个坐标,没法上移,所以系统默认取了当前记录自身,所以计算后的值都是0。如果我们不希望显示0,那么可以加个if条件判断表达式,如果当前位于第一个分组,就输出空字符串,否则输出实际计算后的值,修改后的报表模版如下图所示:

D2单元格对应的表达内容如下图所示:

运行后的效果如下图所示:
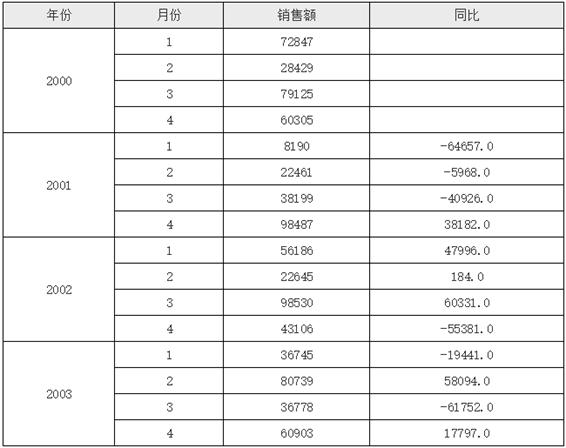
在上面的例子中,我们使用了if判断表达式,当然你也可以换成三元表达式判断或case判断,在这个if判断中,首先我们判断的是&A2==1是否成立,这里的&A2指的是相对于当前单元格A2单元格展开后的序号,在复杂报表组件中,可以采用“&单元格名称”的方式标记某个单元格展开后的序号,需要注意的是,使用“&单元格名称”来标记目标单元格展开后的序号时,当前单元格必须是目标单元格的子格或间接子格;比如,在上面的例子中,使用&A2的单元格是D2,D2是A2单元格的间接子格,这样就可以正确取到A2展开后的序号值。
# 关于&标记的使用
在使用“&单元格名称”来标记目标单元格展开后的序号时,除上需要注意上面描述的内容外,还需要注意,取序号将以他们共同的父格为基准,如果他们有共同的父格,那么将以这个父格里目标单元格的数量来进行序号编排,实现明细型主从报表,对从表数据进行编号时就有体现。
# 逐层累加
报表模版如下图所示:

D2单元格对应的表达式如下:

# 数据集表达式
数据集是报表展示数据的来源,一般情况,定义好数据集后,在数据集对应的字段上双击即可在目标单元格上添加对应的数据绑定信息,然后在其属性面板设置聚合方式、迭代方向等。实际上,在复杂报表组件中,还允许我们在单元格表达式里通过书写表达式来实现单元格与数据集字段的绑定,其语法结构如下:
数据集名称.聚合方式(字段名[,条件,排序方式])
聚合方式与我们双击添加字段绑定后在属性面板上看到的聚合方式基本一致,具体有以下几种类型。
# select(罗列数据)
语法格式如下:
datasetName.select(propertyName[,filter,order])
filter为条件部分,条件可以有多个,多个条件之间用 and 或 or连接,order为是否对当前的propertyName进行排序,可选值有两个desc和asc,既正序和倒序。
| 示例 | 说明 |
|---|---|
| ds1.select(username) | 取数据集ds1中所有的username字段信息 |
| ds1.select(username,age>18) | 取数据集ds1中所有的age属性大于18的username字段信息 |
| ds1.select(username,age>18, desc) | 取数据集ds1中所有的age属性大于18的username字段信息,同时对username字段做倒排序 |
| ds1.select(username,age>18 and age<60, asc) | 取数据集ds1中所有的age属性大于18且小于60的username字段信息,同时对username字段做正排序 |
# group(分组罗列数据)
语法格式如下:
datasetName.group(propertyName[,filter,order])
filter为条件部分,条件可以有多个,多个条件之间用 and 或 or连接,order为是否对当前的propertyName进行排序,可选值有两个desc和asc,既正序和倒序。
| 示例 | 说明 |
|---|---|
| ds1.group(degree) | 对数据集ds1中degree字段进行分组 |
| ds1.group(degree,age>18) | 对数据集ds1中age属性大于18的所有的degree字段进行分组 |
| ds1.group(degree,age>18, asc) | 对数据集ds1中age属性大于18的所有的degree字段进行分组,同时对分组后的degree字段进行正排序 |
# sum(累加数据)
sum是对数据集目标字段进行累加,所以目标字段一定要是一个数字类型,否则就会产生错误,其语法格式如下:
datasetName.sum(propertyName,filter)
与之前函数不同之处在于,sum函数没有order,也就是说不需要排序,原因很简单,因为累加后的值只有一个,所以无需排序。
| 示例 | 说明 |
|---|---|
| ds1.sum(salary, age>30) | 对数据集ds1中age属性大于30的所有对象的salary字段进行累加 |
| ds1.sum(salary) | 对于数据集ds1中的salary字段进行累加 |
# count(统计数量)
count是对数据集对象数量进行统计,其语法格式如下:
datasetName.count(filter)
统计数量不需要指定propertyName及order。
| 示例 | 说明 |
|---|---|
| ds1.count() | 对ds1数据集中对象数量进行统计 |
| ds1.count(age>30) | 统计数据集ds1中对象属性age值大30的所有对象的数量 |
# max(取最大值)
max语法格式如下:
datasetName.max(propertyName,filter)
取最大值没有order。
| 示例 | 说明 |
|---|---|
| ds1.max(salary) | 对于数据集ds1中的salary字段进行比较,取最大值 |
| ds1.max(salary, age>30) | 对数据集ds1中age属性大于30的所有对象的salary字段进行比较,取最大值 |
# avg(取平均值)
avg在取平均值时,如除不尽,则保留8位小数,avg的语法格式如下:
datasetName.avg(propertyName,filter)
取平均值没有order。
| 示例 | 说明 |
|---|---|
| ds1.avg(salary) | 对于数据集ds1中的salary字段取平均值时,如除不尽,则保留8位小数 |
| ds1.avg(salary, age>30) | 对数据集ds1中age属性大于30的所有对象的salary字段取平均值时,如除不尽,则保留8位小数 |
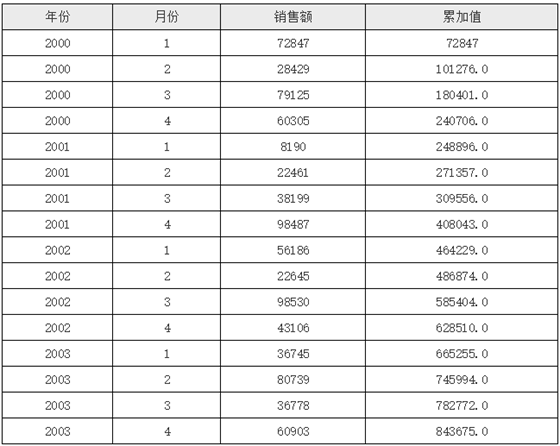
# 取当前单元格值
在复杂报表组件中提供了一种特殊的表达式,用来取当前单元格值,它就是“#”,比如在给某个单元格配置链接时,我们可能需要将当前单元格值作为参数传递给这个链接,那么就可以在链接表达式里输入#,这就将会将当前单元格值取出来,传递过去,如下图所示:
除此之外,如果在#后面加上.后接具体的属性名,那么还可以取到与当前单元格绑定的数据对象的具体属性值,如:#.id,表示取与当前单元格绑定的对象的id属性值,当然如果当前单元格内容不是一个数据集类型的,那么就会返回null,同样如果当前单元格绑定的数据集属性运行时值有多个,那么它只会取第一个对象的对应的属性值。
# 计算函数
在前一小节中,我们介绍了表达式,实际上函数也是表达式的一种。在复杂报表组件当中提供了大量的内置函数,通过这些内置函数,可以实现各种各样的报表计算功能。函数语法格式如下:
函数名([表达式,表达式...])
下面我们就来逐个介绍复杂报表组件内置的函数。
# 常用函数
# count函数(统计数量)
count函数是对给定的表达式在计算后对象数量进行统计。
| 示例 | 说明 |
|---|---|
| count(C1) | 统计相对当前所在单元格,目标C1单元格数量 |
| count(C1{age>20}) | 统计相对当前所在单元格,目标C1单元格绑定对象的age属性大于20的C1单元格数量 |
| count(C1,C2) | 统计相对当前所在单元格,目标C1单元格以及C2单元格加在一起的数量 |
# avg函数(求平均值)
avg函数是对给定的表达式在计算后值求平均值,avg函数要求各个表达式计算后的值必须是数字,否则将产生错误。
| 示例 | 说明 |
|---|---|
| avg(C1) | 相对当前单元格,求C1单元格的平均值 |
| avg(C1,C2) | 相对当前单元格,求C1和C2单元格的平均值 |
| avg(C1{age>20}) | 相对当前单元格,取到绑定对象属性age大于20的C1单元格值的平均值 |
| avg(C1{age>20},C2{salary>2000 and degree=='本科'}) | 相对当前单元格,取到所有绑定对象属性age大于20的C1单元格值以及绑定对象属性salary大于2000且degree属性等于本科的C2单元格的值进行求平均值 |
# max函数(求最大值)
max函数是对给定的表达式在计算后值求其中的最大值,max函数要求各个表达式计算后的值必须是数字,否则将产生错误。
| 示例 | 说明 |
|---|---|
| max(C1) | 相对当前单元格,求C1单元格的最大值 |
| max(C1{age>20}) | 相对当前单元格,取到绑定对象属性age大于20的C1单元格值的最大值 |
| max(C1,C2) | 相对当前单元格,求C1和C2单元格的最大值 |
| max(C1{age>20},C2{salary>2000 and degree=='本科'}) | 相对当前单元格,取到所有绑定对象属性age大于20的C1单元格值以及绑定对象属性salary大于2000且degree属性等于本科的C2单元格的值进行求最大值 |
# row函数(取行号)
取当前单元格所在行的行号,这个函数比较简单,它没有参数。
| 示例 | 说明 |
|---|---|
| row() | 取当前单元格所在行的行号 |
# column函数(取列号)
取当前单元格所在列的列号,这个函数比较简单,它没有参数。
| 示例 | 说明 |
|---|---|
| column() | 取当前单元格所在列的列号 |
# order函数(排序)
order函数需要两个参数,第一个为要进行排序的对象表达式,第二个是一个布尔值,用来设置排序方式,true正序,false为倒序。
| 示例 | 说明 |
|---|---|
| order(C1,false) | 相对当前单元格,取到所有C1单元格值,对这些值进行倒排序,返回排序好的结果集合 |
| order(C1{age>18},true) | 相对当前单元格,取到与C1单元格绑定的对象属性age值大于18的所有C1单元格值,对这些值进行正排序,返回排序好的结果集合 |
# list函数(罗列数据)
取到表达式中定义所有数据,并以集合形式返回。
| 示例 | 说明 |
|---|---|
| list(C1) | 相对当前单元格,取到所有C1单元格值以集合形式返回 |
| list(C1,C2{age>20}) | 相对当前单元格,取到所有C1单元格值及C2单元格中age属性大于20的所有C2单元格值以集合形式返回 |
# param函数(取参数)
param函数用来获取外部传入的参数,它需要一个参数,用于指定要获取的参数名称。
| 示例 | 说明 |
|---|---|
| param("deptId") | 获取外部传入的名为deptId的参数值 |
| param(C1) | 相对于当前单元格,取到C1单元格的值,如果有多个C1单元格则么第一个,然后以这个C1单元格值作为参数名称,获取外部对应的参数值。 |
# formatdate函数(格式化日期)
对给定的日期参数进行格式化,它至少需要一个参数,第一个参数是要格式化的日期类型的对象,第二个参数是可选的,用于定义格式化采用的模式,如不指定则用默认的:
yyyy-MM-dd HH:mm:ss
来进行格式化。
| 示例 | 说明 |
|---|---|
| formatdate(C1) | 取到C1单元格值,这个值必须是日期类型,然后按yyyy-MM-dd HH:mm:ss来进行格式化成字符串输出 |
| formatdate(C1,"yyyyMMdd") | 取到C1单元格值,这个值必须是日期类型,然后按yyyyMMdd来进行格式化成字符串输出 |
# formatnumber函数(格式化数字)
对给定的参数进行格式化,它至少需要一个参数,第一个参数是要格式化的数字对象,要保证这个参数值取到后可以转换成日期,否则将发生错误;第二个参数是可选的,用于定义数字格式化采用的模式,如不定义,则采用默认的#来进行格式化。
| 示例 | 说明 |
|---|---|
| formatnumber(C1) | 取到C1单元格值,这个值必须可以转换成数字,然后按#来进行格式化成字符串输出 |
| formatnumber(C1,"#,###.00") | 取到C1单元格值,这个值必须可以转换成数字,然后按#,###.00来进行格式化成字符串输出 |
# get函数(获取指定位置数据)
get函数是2.1.2版本中新增的,它的作用是获取数据集中指定位置的对象或对象的某个属性值。get函数可以有三个参数,第一个为目标集合对象、第二个为数据位置、第三个是对象属性,其中第一个参数是必须的,后面两个参数为可选。
| 示例 | 说明 |
|---|---|
| get(A3,4) | 获取所有A3单元格值,从中取第四个值并返回。 |
| get(ds1.select(employee_name)) | 从ds1数据集中获取第1个对象值,并将其返回。第二个位置参数没有指定默认取集合第一个对象 |
| get(ds1.select(employee_name),2) | 从ds1数据集中获取第2个对象值,并将其返回。 |
| get(ds1.select(employee_name),2,"deptId") | 从ds1数据集中获取第2个对象值,并从这个对象里取deptId属性值并返回。 |
# 分页相关函数
所谓分页相关函数,是指这些函数是在分页的时候进行计算,比如计算当前页有多少条记录、当前页某个单元格值累加后是多少、平均值是多少、最大值是多少等等。
一般来说,分页相关函数多用在行类型为“重复表头”或“重复表尾”的行中的单元格里。同时,需要注意的是,分页相关函数只会在分页预览时显示,这点需要注意。
# pcount函数
统计当前页下表达对应值的数目,与count函数的使用方法基本一致,不同之处在于pcount只会统计当前页中对应的表达式内容的数目。
| 示例 | 说明 |
|---|---|
| pcount(C1) | 统计当前页中,C1单元格数目 |
| pcount(C1,D2{D2>10000}) | 统计当前页中,C1单元格和当前页中所有D2单元格值大于10000的D2单元格数目 |
# psum函数
将当前页下表达式对应的所有值进行累加,与sum函数对应,不同的是psum只针对当前页。
| 示例 | 说明 |
|---|---|
| psum(C1) | 将当前页中,所有C1单元格值进行累加 |
| psum(C1,D2{D2<10000}) | 将当前页中,所有C1单元格值以及值小于10000的D2单元格值累加起来 |
# pmax函数
比较当前页中,表达式对应的值,找出其中最大的那个值,与max函数对应,只是pmax只针对当前页。
| 示例 | 说明 |
|---|---|
| pmax(C1) | 比较当前页中所有C1单元格值,找出最大值。 |
| pmax(C1,D2,E2{E2>1000}) | 比较当前页中,所有C1、D2以及值大于1000的E2单元格值,找出其中最大的。 |
# pmin函数
比较当前页中,表达式对应的值,找出其中最大的那个值,与max函数对应,只是pmax只针对当前页。
| 示例 | 说明 |
|---|---|
| pmin(C1) | 比较当前页中所有C1单元格值,找出最小值。 |
| pmin(C1,D2,E2{E2>1000}) | 比较当前页中,所有C1、D2以及值大于1000的E2单元格值,找出其中最小的。 |
# page函数
输出当前所在页的页码,该函数没有参数。
| 示例 | 说明 |
|---|---|
| page() | 输出当前所在页的页码 |
# pages函数
输出当前报表一共有多少页,该函数没有参数。
| 示例 | 说明 |
|---|---|
| pages() | 输出当前报表一共有多少页 |
# 数学函数
# abs函数(绝对值)
求参数的绝对值,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| abs(-233) | 求-233绝对值,计算后的值是233 |
| abs(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值返回其绝对值 |
# ceil函数(最小值)
返回大于或等于一个给定数字的最小整数,如果参数值为小数将舍弃小数点后面的小数部分,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| ceil(32.32) | 计算后值为33 |
| ceil(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值返回其最小值 |
# floor函数(最大值)
返回小于或等于一个给定数字的最大整数,如果参数值为小数将四舍五入小数点后面的小数部分,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| floor(32.52) | 计算后值为32 |
| floor(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值返回其最大值 |
# chn函数(数字转中文)
将一个数字转化成中文,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| chn(213) | 计算后的值为:贰佰壹拾叁 |
| chn(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值,再转化成中文 |
chn函数使用注意事项
chn函数转换数字即可是整数,也可是小数,如果是小数支持后面最多两位小数,如果实际小数过多,chn函数会先进行四舍五入,然后再进行转换。
# cos函数(求余弦)
求参数的余弦值,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| cos (213) | 计算后的值为:0.8090276252864301 |
| cos(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值,再求其余弦值 |
# sin函数(正弦)
| 示例 | 说明 |
|---|---|
| sin(213) | 计算后的值为:-0.58777 |
| sin(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值,再求其正弦值 |
# tan函数(正切)
求参数的正切值,参数值计算后数据类型必须是数字,否则会报错。
# exp函数(方法用于返回自然数底数e的参数次方)
求参数的自然数底数e的参数次方,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| expr(213) | 计算后的值为:3.196867565323994E921 |
| expr(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值,再求其自然数底数e的参数次方 |
# log10函数(返回以10为底的对数值)
求参数以10为底的对数值,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| log10(213) | 计算后的值为:2.3283796034387376 |
| log10(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值,再求其以10为底的对数值 |
# log函数(自然对数)
求参数自然对数值,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| log(213) | 计算后的值为:5.3612921657094255 |
| log(C1) | 相对当前单元格,取到C1单元格的值,如果有多个则取第一个值,再求其自然对数值 |
# median函数(中位数)
求一组数据的中位数,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| median(12,42,31) | 运行结果为31 |
| median(C1) | 相对当前单元格,取到C1单元格的所有值,再取这些值中位数 |
# mode函数(众数)
求一组数据的众数,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| mode(12,42,3,12) | 运行结果为12 |
| mode(C1) | 相对当前单元格,取到C1单元格的所有值,再取这些值众数 |
| mode(C1,C2) | 相对当前单元格,取到C1单元格和C2单元格的所有值,再取这些值众数 |
# vara函数(方差)
求一组数据的方差,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| vara(12,42,3,12) | 运行结果为209.25 |
| vara(C1) | 相对当前单元格,取到C1单元格的所有值,再取这些值方差 |
| vara(C1,C2) | 相对当前单元格,取到C1单元格和C2单元格的所有值,再取这些值方差 |
# stdevp函数(标准差)
求一组数据的标准差,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| stdevp(12,42,3,12) | 运行结果为14.75424 |
| stdevp(C1) | 相对当前单元格,取到C1单元格的所有值,再取这些值标准差 |
| stdevp(C1,C2) | 相对当前单元格,取到C1单元格和C2单元格的所有值,再取这些值标准差 |
# pow函数(返回第一个参数的第二个参数次方)
pow函数需要两个参数,第一个为需要计算的数字或表达式,第二个为具体的次方。
| 示例 | 说明 |
|---|---|
| pow(3,2) | 表示计算3的2次方值,运算后的结果为9 |
| pow(C1,3) | 相对当前单元格,取到C1单元格的值,如果取到的C1单元格有多个,则取第一个,再对其值求3次方 |
# random函数(随机数)
生成一个随机数,可以有一个数字类型的参数或表达式,如果有参数,那么以这个参数作为生成随机数字的种子,如果没有则生成一个0~1之间的随机数。
| 示例 | 说明 |
|---|---|
| random() | 生成一个0~1之间的随机数 |
| random(10) | 生成一个1~10之间的随机数 |
| random(C1) | 相对当前单元格,取到C1单元格的值,如果取到的C1单元格有多个,则取第一个,再将这个值作为种子生成一个随机数 |
# round函数(四舍五入)
对一个小数进行四舍五入,它需要两个参数,第一个参数要进行四舍五入的小数或表达式,第二个为一个可选的要保留的小数位数,如果没有,则不保留小数。
| 示例 | 说明 |
|---|---|
| round(32.12) | 计算后的值为32 |
| round(32.123,2) | 计算后的值为32.12 |
| round(C1,2) | 相对当前单元格,取到C1单元格的值,如果取到的C1单元格有多个,则取第一个,然后对这个值做保留两位小数的四舍五入操作 |
# sqrt函数(平方根)
求一个数字或表达式计算后值的平方根,参数值计算后数据类型必须是数字,否则会报错。
| 示例 | 说明 |
|---|---|
| sqrt(2) | 计算后的值为:1.414214 |
| sqrt(C1) | 相对当前单元格,取到C1单元格的值,如果取到的C1单元格有多个,则取第一个,然后对这个值进行取平方根计算 |
# 日期函数
# date函数(日期)
输出日期,date函数可以有一个参数,就是日期格式,如果没有则采用yyyy-MM-dd HH:mm:ss格式输出日期。
| 示例 | 说明 |
|---|---|
| date() | 以yyyy-MM-dd HH:mm:ss格式输出当前日期,如:2010-08-15 08:45:10 |
| date('yyyy年MM月dd日') | 以yyyy年MM月dd日格式输出当前日期,如:2010年08月15日 |
# day函数(天)
输出当前在月份中的天,该函数没有参数。
| 示例 | 说明 |
|---|---|
| day() | 可能输出15,表示当前为15日 |
# month函数(月)
输出当前月份,该函数没有参数。
| 示例 | 说明 |
|---|---|
| month() | 可能输出8,表示当前为8月份 |
# week函数(星期)
输出当前是星期几,该函数没有参数。
| 示例 | 说明 |
|---|---|
| week() | 输出值可能是“星期三”,表示当前为星期三 |
# year函数(年)
输出当前年份,该函数没有参数
| 示例 | 说明 |
|---|---|
| year() | 输出结果为2010,表示当前为2010年 |
# 字符串函数
# indexOf函数(位置)
用于返回一个字符串,在目标字符串中的位置,该函数至少需要两个参数,第一个为目标字符串,第二个为要查找的字符串,如果有三个参数,那么第三个就是开始查找的位置信息,第三个参数必须是一定大于等于0的数字。
| 示例 | 说明 |
|---|---|
| indexof('中华人民共和国','共和') | 表示要从"中华人民共和国"这个字符串中找到“共和”字符串的位置 |
| indexof('中华人民共和国','共和',2) | 表示要从"中华人民共和国"这个字符串中第二个字符开始始,找到“共和”字符串的位置 |
| indexof(C1,"人民",2) | 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,再从这个值中第2个位置开始找到“人民”字符串的位置 |
# length函数(长度)
求目标字符串长度,该函数必须要有一个参数。
| 示例 | 说明 |
|---|
length("中华人民共和国") 计算结果为7 length(C1) 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,然后计算这个值长度
# lower函数(转小写)
将参数中英文全部转为小写,该函数必须要有一个参数。
| 示例 | 说明 |
|---|---|
| lower("Super man") | 计算后的结果为:super man |
| lower(C1) | 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,然后将这个值中所有英文转换成小写 |
# upper函数(转大写)
将参数中英文全部转为大写,该函数必须要有一个参数。
| 示例 | 说明 |
|---|---|
| upper("Super man") | 计算后的结果为:SUPER MAN |
| upper(C1) | 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,然后将这个值中所有英文转换成大写 |
# replace函数(替换字符串)
这个函数需要有三个参数,第一个是目标字符串,第二个是要被替换的字符串,第三个是要替换的字符串。
| 示例 | 说明 |
|---|---|
| replace("他是一个好人","他","她") | 计算结果为:她是一个好人 |
| replace(C1,"他","她") | 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,然后再将这个值中所有“他”换成“她” |
# substring函数(子字符串)
该函数允许有三个参数,第一个是目标字符串,第二个为开始截取的位置,第三个为截取结束的位置。
| 示例 | 说明 |
|---|---|
| substring("他是一个好人",2) | 运行结果为:一个好人 |
| substring("他是一个好人",2,4) | 运行结果为:一个 |
| substring(C1,2,10) | 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,然后再取这个值中第2到第10个字符之间内容 |
# trim函数(去空格)
去除目标字符串两边空格,该函数要求必须要有一个参数。
| 示例 | 说明 |
|---|---|
| trim(" 一个好人 ") | 运行结果为: 一个好人 |
| trim(C1) | 相对于当前单元格,找到C1单元格,如果C1单元格有多个,则取第一个单元格值,然后再将这个值两边可能存在的空格全部去除 |
# json函数(解析JSON字符串)
该函数可以解析指定的目标JSON字符串,并取出指定的属性值。json函数需要有两个参数,第一个是目标JSON字符串对象,第二个是要取出的属性名。
| 示例 | 说明 |
|---|---|
| json(emp.select(other),'name') | 取出数据集emp中other属性值对应的字符串,将其转换为JSON,再从这个JSON中取name属性值。 |
| json(emp.select(other),'company.name') | 取出数据集emp中other属性值对应的字符串,将其转换为JSON,再从这个JSON中取company子对象下的name属性值。 |
对JSON字符串的要求
json函数在解析JSON字符串时,要求必须是标准的JSON字符串,比如下面这样的:
{"name":"superman","age":32,"company":{"name":"bstek","address":"SHANGHAI CHINA"}}
也就是key属性也需要用“”包裹的,如果是下面这种类型的JSON字符串就解析时就会产生错误:
{name:"superman",age:32,company:{name:"bstek",address:"SHANGHAI CHINA"}}
# 报表下钻
报表下钻是一种可视化图表的交互方式,能够将选中元素对应类目下更为具体的数据通过下一层级图表显示出来。下钻配置是写在表达式下格式化中,如下:
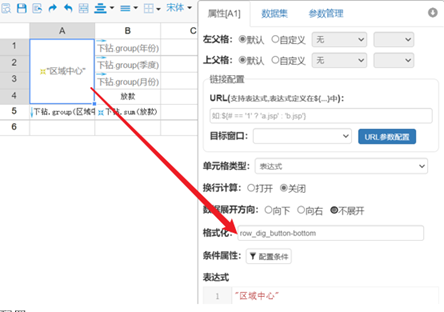
格式化配置:
| 示例 | 说明 |
|---|---|
| row_dig_button-bottom | 表示维度依次递减 |
| row_dig_button-top | 表示维度依次递减增 |
| row_dig_level-1-row | 其中 1 代表为第一行维度 其中 row 代表下钻时把当前行去除 |
| row_dig_level-1-col | 其中 col 代表下钻时把当前列去除(包含合并单元格) |
使用格式化,格式化写在括号中即可 :
row_dig_level-1-col(#.00)
向右展开配置如下:
效果如下:

向下展开配置如下:
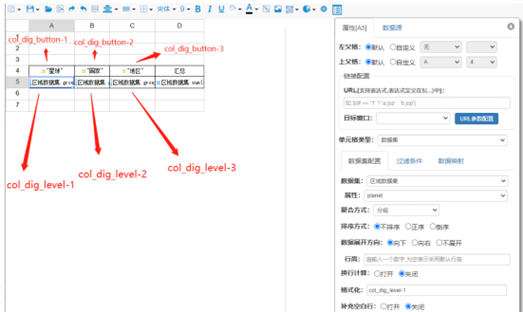
效果如下:


# 条件属性
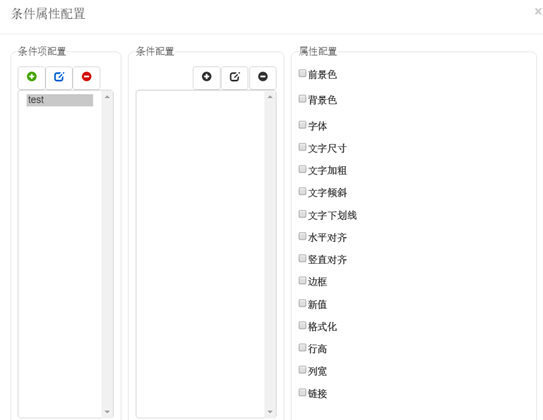
条件属性是复杂报表组件中提供的一种快捷的修改报表外观的方法。打开配置条件属性窗口,通过为每一项条件属性配置条件以及条件满足后执行的改变报表外观的动作,从而快速实现报表样式的灵活定义。目前类型为”数据集“或”表达式“的单元格都支持配置条件属性,配置方法就是选中这两种类型的单元格,点击属性面板上 按钮即可,点击后将弹出条件属性配置窗口,如下图
# 行类型
在报表设计器中,选择任意一行或单元格,点击右键,就可以在弹出菜单中看类类型的定义,如下图所示:
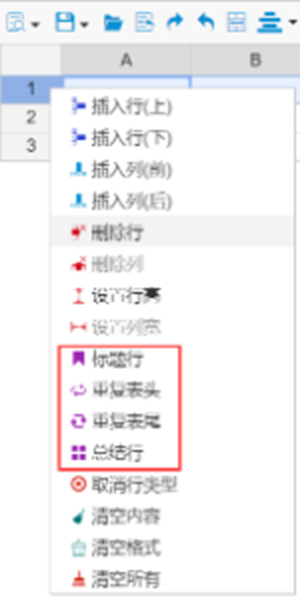
从右键菜单中可以看到,复杂报表组件支持将特定行定义成四种特殊类型,分别是:标题行、重复表头行、重复表尾行以及总结行,这些行类型主要是在分页时起作用。
# 标题行
所谓标题行,就是在报表计算后分页时只会出现在第一页第一行的行,如果定义了多个行为标题行类型,那么这些行将在报表运行后分页输出时第一页最前面插入标题行。
需要注意的是,我们在报表中可以将位于任意位置的行定义成标题行,但报表计算分页输出时,总会将这些定义为标题行的行放在报表的第一页最前端显示。
# 重复表头行
与标题行不同的是,定义为重复表头行的行,在报表计算分页输出时会将定义成重复表头行的行放在每一页的前端进行显示。
如果当前报表中定义的有标题行,那么对于第一页,标题前将位于最上面,其下才是重复表头行定义的行。
# 重复表尾行
与重复表头行类型,它也会在报表计算分页输出时放在每一页中显示,只是它会在每一页的最下端显示。总结行
与标题行对应,总结行会出现在报表计算后分页输出时最后一页的最下端显示。
如果当前报表中定义了重复表尾行,那么在报表计算后分页输出的最后一页中总结后将位于重复表尾行下方显示。
# 补充空白行与分页
选中任意一个包含数据集属性的单元格,在属性面板上可以看到它有个名为“补充空白行”的属性,默认该属性处于关闭状态,当我们将其打开后,就需要输入具体的“数据行倍数”,如下图所示:
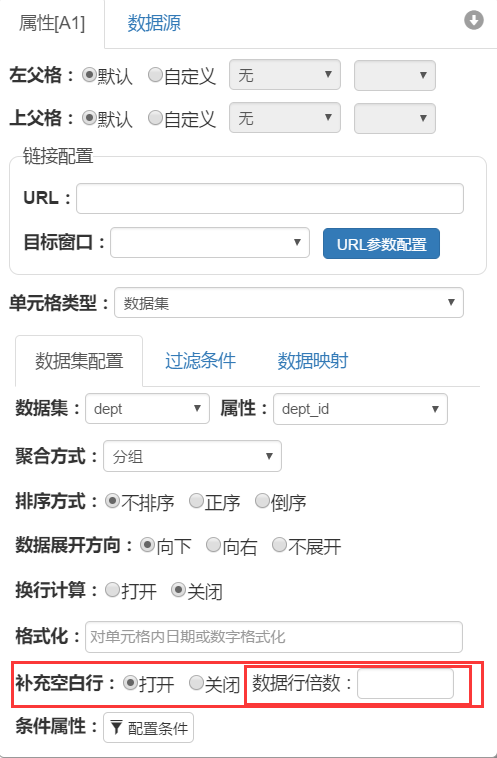
在上图中,一旦我们将某个包含数据集的单元格的补充空白行属性打开,并设置了具体的数据行倍数,那么报表在计算当前单元格对应的数据时,会根据这里设置的具体倍数来决定是否填充空白行,以及填充多少行空白行。比如当前单元格对应的数据集属性,在报表计算后共有3条数据,而我们又将该单元格补充空白行属性打开,并设置了数据行倍数为5,那么引擎就会拿当前数据集计算后的条数,也就是3 mod 数据行倍数值5,其结果是2,那么引擎将在这个单元格展开后的最后一行添加两行空白行(如果当前单元格展开后的条数是10,因为10 mod 5等于0,那么引擎将不添加空白行)。
对于添加的空白行,引擎将根据当前单元格所在行对应的每一列中单元格的样式来设置空白行中每列每个单元格的样式,也就是说,如果当前单元格所在行每列对应的单元格都没有边框线,那么添加的空白行每列中每个单元格都没有边框线,反之亦然。
看一个例子,在下图中,报表模版A1单元格的填充空白行属性打开,数据行倍数是5,如下图所示:
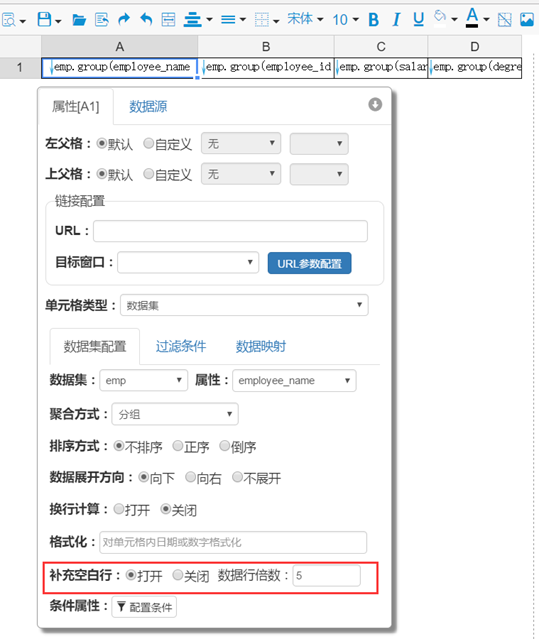
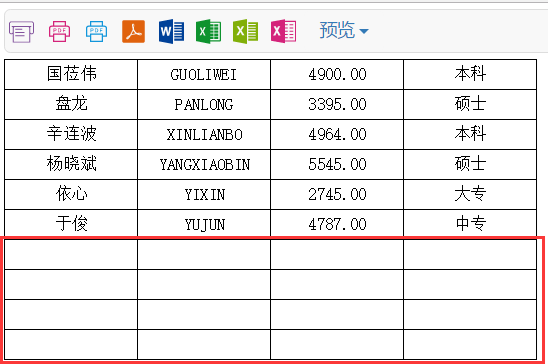
在A1单元格对应的数据集属性中,报表运行时数据共6条,6 mod 5=1,所以引擎还会在最后一个A1单元格所在行后添加4行空白行(因为要求数据行是5的倍数,所以实际运行会加四行空白行),运行后效果如下图所示:
了解这些内容后,再配合之前介绍的条件属性以及行类型,就可以做出一些复杂的样式及特殊分页要求的主从明细型报表。
下图中是一个典型的主从明细型报表,在这个报表中,我们就将行类型,填充空白行,条件属性等功能进行结合使用,如下图所示:
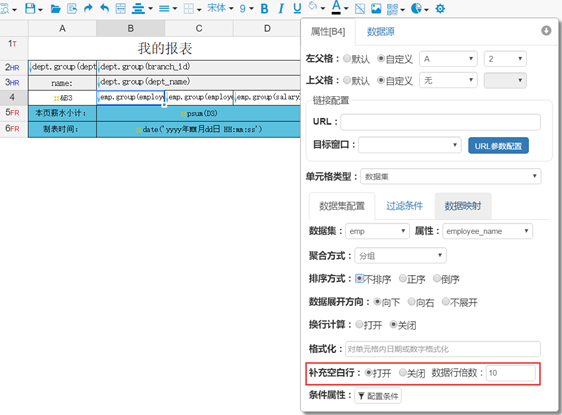
在B4单元格我们将其补充空白行属性打开,并设置数据行倍数为10,同时选中B4单元格,点击条件属性的配置条件按钮,可以看到我们也为其配置了一个条件,如下图所示:
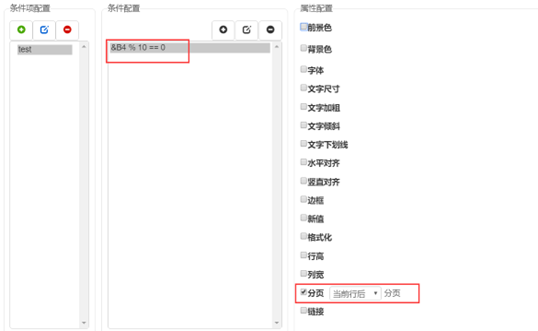
在这里,我们添加了一个条件表达式,那就是&B4 % 10==0是否成立,如果成立,那么就在这个单元格所在行后进行分页。
# 关于&B4
&B4是复杂报表组件中提供的一个表达式,用来获取对应单元格展开后的行号,这里&B4 % 10就是拿B4单元格展开后的行号值与10除求余,看余数是否等于0,如果是就在这个单元格所在行后进行分页。
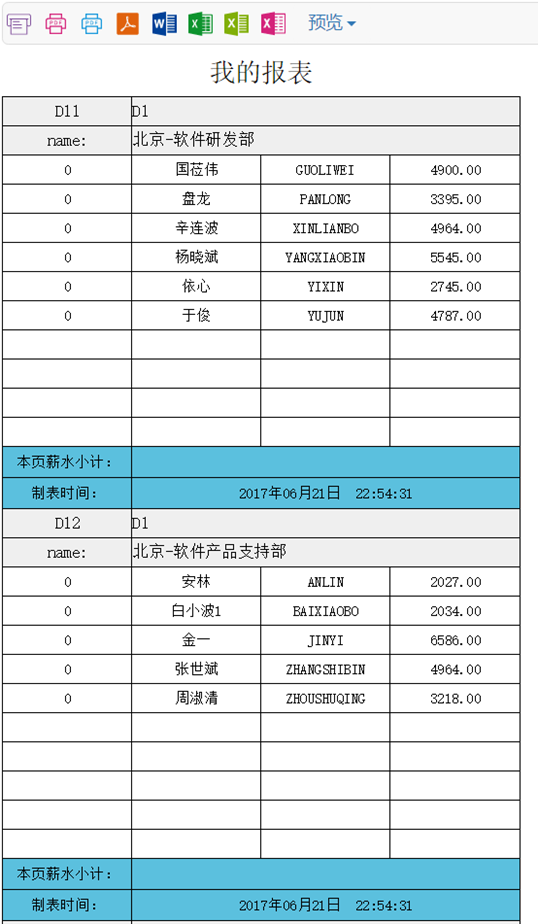
运行后的报表如下图的所示:
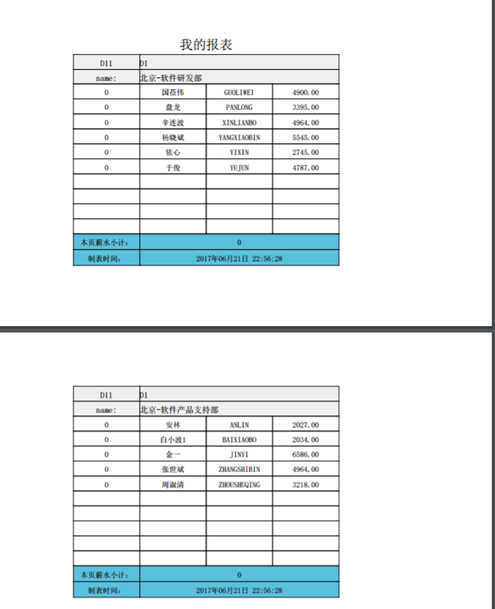
点击打印,可以看到如下图所示的打印预览效果:
如果我们将B4所在行所有单元格边框线去掉,那么生成的效果就是下面的样子:
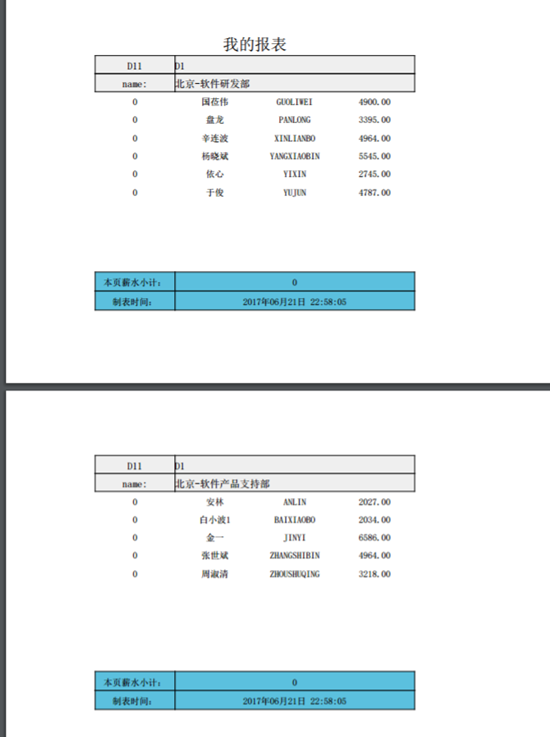
在这个例子当中,报表打印输出时之所以会出现上图所示效果,是因为当我们为B4单元格定义了填充空白行的数据倍数为10的时候,那么对于每个明细下的B4单元格展开后的数据量行数都会是10的倍数,如果不是则会自动填充空白行以达到10的倍数。同时对于B4单元格我们又为其设置了条件属性,条件是&B4 % 10 =0,也就是判断B4单元格展开后当前行号整除10的余数是不是0,如果是就在B4单元格所在行后进行分页。通过上述关键的两个设置就实现了这种每页行数一样(带有填充空白行)效果主从明细类报表。
# 关于分页
需要注意的是,在实现这种类型报表时,在采用“自动”类型的分页方式时,要保证每一页的行对应的所有行高,不要超过当前页可用高度;当采用“固定行数”类型的分页方式时,要保证固定行数分页的行数值,与条件属性中对应的分页配置匹配。
# 套打
复杂报表组件支持套打功能,我们可以设计报表的背景图,这样就可以快速完成套打的报表模版设计工作。
要为报表模版设置背景图,可以点击工具栏上的设置图标,在弹出窗口中定义要采用的背景图URL即可,如下图所示:
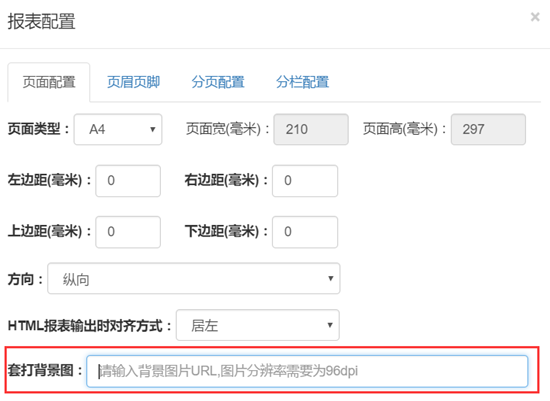
在设计器中指定背景图片的URL时,看到张背景图
对于套打而言,一般情况下,我们首先需要拿到具体的实物单据,然后进行扫描,比如可以以300dpi的分辨率进行扫描,扫描后的图片用可以用PHOTOSHOP之类的图片处理软件打开,将图片分辨率设置为96dpi即可,最后将这张96dpi的图片作为报表模版的背景图同时将报表模版的页面尺寸与扫描件的尺寸对应上,并设置上下左右的页边距为为0,这样就可以开始套打报表模版的设计工作了。
对于复杂报表组件而言,一旦报表模版设置了背景图片,在HTML预览时会显示背景图片,但在导出PDF、WORD、EXCEL等格式的文件时则不会输出对应的背景图片,这样直接打印PDF、WORD之类输出文件,就可以实现报表功能。下图中是一张带背景图的报表模版文件:
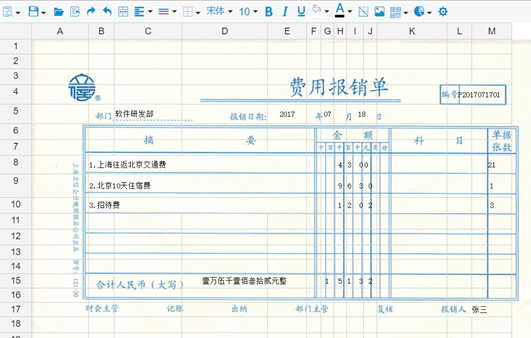
在这张报表模版当中,我们用的数据都是静态的,当然对于来自数据集或表达式中的动态数据设置方法也是一样,点击HTML预览按钮,可以看到如下图所示效果:

在需要套打的报表模版设计过程中,选择好背景图后,一般我们需要先从最为密集行列部位开始设计,最后才是最简单的部位,实际使用时,具体位置还需要我们慢慢微调方可达到最佳位置效果。